
Glossaires - Informations générales
Sommaire
L'interprétation de la présence des données
Dans un glossaire, 2 sortes de fiches sont présentes pour présenter les données d'une déclaration :
- Les fiches des zones
- Les fiches des blocs
Pour chacune de ces données - tant les blocs que les zones - une présence a été définie. Outre la présence d'une certaine zone, il faut par conséquent toujours considérer la présence du bloc dans lequel figure la zone.
Prenons un exemple :
Le bloc 90036 - Commentaire à la déclaration a une présence Facultatif.
Cela signifie que l'on peut, si on le souhaite, retourner l'ensemble des zones de ce bloc. Dans notre exemple, le bloc ne contient qu'une seule zone, à savoir 00126 - Zone texte libre.
La zone 00126 - Zone texte libre a une présence Indispensable.
Cela signifie que si l'on choisit de reprendre le bloc 90036 - Commentaire à la déclarationdans la déclaration, cette zone doit obligatoirement être complétée.
Autrement dit, Il existe des conditions supplémentaires au niveau des zones, valables lorsque le bloc est repris.
Examinons cette règle au niveau XML.
Le tag xml du bloc est <CommentDeclaration>.
Le tag xml de la zone en question est <CommentOfDeclaration>.
Si aucun commentaire n'est souhaité, tant le bloc que la zone doivent être ignorés.
On ne peut donc avoir ceci :
<CommentDeclaration></CommentDeclaration>Si un commentaire est souhaité, tant le bloc que la zone doivent être présents :
<CommentDeclaration>
<CommentOfDeclaration>TEST</CommentOfDeclaration>
</CommentDeclaration>Conclusion :
La présence déclarée au niveau de la zone (voir la fiche correspondant à la donnée dans le glossaire), ne suffit pas à déterminer si cette donnée doit ou non être reprise dans la déclaration.
Etant donné que les zones sont regroupées en blocs fonctionnels, la présence d'une zone est subordonnée à la présence du bloc dont la zone fait partie. En effet, même si une zone est déclarée indispensable, elle peut ne pas figurer dans la déclaration si le bloc auquel elle appartient est un bloc facultatif.
Les fiches relatives aux blocs doivent donc également être consultées (à savoir "la présence") pour juger si une zone relative à une certaine donnée doit figurer dans la déclaration.
Utilisation du Tag <Location> (zone 00295 - "Localisation de l'erreur dans l'arborescence")
Ce tag a comme objectif de nous permettre de localiser de manière univoque l'endroit où s'est produite une erreur dans une structure hiérarchique et donc dans un document XML. De ce fait nous allons faire en sorte que chaque élément d'un document XML puisse être localiser grace à un « chemin ».
Etant donné qu'un document XML est une stucture hiérarchique, ce dernier peut être représenté par un arbre. De plus, tous les éléments de cet arbre peuvent être numérotés.
Nous allons les numéroter de la sorte : le numéro attribué à un élément correspondra à sa position (quantième fils) par rapport à son père. De ce fait si un élément a comme numéro n, cela signifie que c'est le n-ème élément fils du père.
Soit le fichier XML suivant :
<Voiture>
<interieur>
<NombreSiège>5</NombreSiège>
<VitresElectriques>Avant<VitresElectriques>
</interieur>
<extérieur>
<NombrePorte>6</NombrePorte>
<PeintureMetal>OUIn<PeintureMetal>
<Longueur>4,23</Longueur>
</extérieur>
</Voiture>Si nous supposons que les seules valeurs permises pour la donnée <PeintureMetal> sont «OUI» ou «NON», nous remarquons que le fichier comporte une erreur. En effet, la zone contient « OUIn » comme valeur.
Voici l'arborescence associée à ce document :
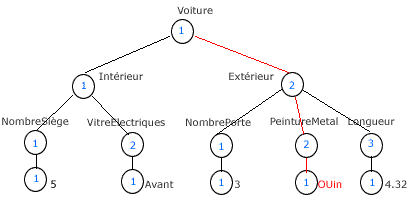
L'erreur detectée dans la donnée « PeintureMetal » sera localisée de façon univoque de la manière suivante :
<Location>1,2,2,1</Location>Informations générales sur les contrôles DRS
Le traitement des DRS, que ce soit via le canal Web (SP10) ou via le canal Batch (SP07), nécessite en plus des contrôles de schéma une série de contrôles appelés contrôles croisés. Ces contrôles croisés intègrent en fait deux types de contrôles :
- des contrôles croisés au sens strict (contrôle de forme trop complexes pour être effectués au niveau du schéma),
- des contrôles de contenu (effectués via appels à des services de base).
Exemples de contrôle croisé :
- Vérifier que la donnée 00045 (OccupationEndingDate) est postérieure ou égale à la donnée 00044 (OccupationStartingDate).
- Vérifier que si la donnée 00016 (System5) vaut 1 alors la donnée 00047 (WorkingDaysSystem) doit être égale à 500.
- Vérifier que la donnée 00112 est présente si la donnée 00378 (EndYearBonusCode) vaut 3 OU (la donnée 00378 vaut 4 ET les données 00387 (EndYearBonusAmount) ET 00111 (EndYearBonusValue) ne sont pas renseignées)
Exemple de contrôle de contenu :
Vérifier que:
- si la date du risque social est dans le trimestre en cours, la donnée 00011 (NOSSRegistrationNbr) doit être présente dans le répertoire "Identification de l'employeur" et la date du risque social doit être comprise entre date d'inscription et date de suppression de ce matricule dans le répertoire.
- si la date du risque social est antérieure au trimestre en cours, la donnée 00011 (NOSSRegistrationNbr) doit être présente et active dans le répertoire "Fichier des Codes" à la date du risque social.
Dans tous les cas, si le résultat d'un contrôle est faux, une anomalie est générée (contenant un code anomalie tel que stipulé dans le glossaire) et apparaîtra dans la Notification correspondant à la DRS contrôlée.
Par exemple, le code anomalie correspondant à l'exemple de contrôle de contenu précédent est 00011-051.
A noter pour finir que certains contrôles sont communs à plusieurs secteurs/scénarii, d'autres sont spécifiques.